
Telset.id – Qualcomm secara resmi memperkenalkan arsitektur near-memory compute terbaru mereka yang disebut High-Bandwidth Compute (HBC). Inovasi ini diklaim mampu memecahkan hambatan klasik yang dikenal sebagai memory wall, sebuah batasan performa yang selama ini menjadi kendala utama dalam pemrosesan AI.
Dalam pengumuman pada Rabu lalu, Qualcomm mengungkapkan bahwa arsitektur HBC dirancang untuk mengatasi keterbatasan bandwidth memori yang seringkali menghambat skalabilitas performa AI. Pendekatan yang digunakan Qualcomm terbilang langsung: perusahaan memisahkan akselerator AI dari system-on-chip (SoC) dan menempatkannya langsung di bawah tumpukan DRAM LPDDR.
Akselerator HBC terhubung ke tumpukan LPDDR menggunakan through-silicon vias untuk memberikan bandwidth dan kapasitas maksimal tanpa harus menggunakan memori HBM yang mahal dan kemasan canggih. Meskipun Qualcomm tidak mengungkapkan angka bandwidth aktual yang diberikan HBC, perusahaan mengklaim bahwa arsitektur ini menawarkan bandwidth-per-watt 6X lebih tinggi dibandingkan HBM dan kapasitas lebih dari 200X dibandingkan SRAM on-chip.

“Kami telah memisahkan akselerator AI dari XPU dan menempatkan XPU langsung di bawah tumpukan DRAM,” kata Tony Pialis, Executive Vice President dan General Manager Data Center Business di Qualcomm. “Ini sangat penting karena memberi kami keunggulan performa SRAM dengan kepadatan dan kapasitas memori bertumpuk. Efeknya, kemacetan yang terkait dengan HBM hilang.”
Pialis menambahkan bahwa nilai bagi industri adalah konsumsi daya yang lebih rendah, panas yang lebih sedikit, dan penghapusan interposer silikon mahal yang digunakan oleh solusi HBM. Perusahaan juga dapat menggunakan beberapa tumpukan HBC dalam satu perangkat komputasi menggunakan kemasan standar, yang memberikan keunggulan performa-per-biaya yang signifikan.
Konsep menempatkan DRAM di atas atau di samping logika sebenarnya bukan hal baru. Semua produsen DRAM telah bereksperimen dengan arsitektur near-memory compute, namun gagal membuatnya populer. Baru-baru ini, GUC, sebuah perusahaan jasa desain ASIC fabless, mengusulkan teknologi DRAM-on-Logic (DoL) yang menempatkan satu hingga empat lapisan DRAM di atas logika untuk mendapatkan bandwidth memori sekitar 5 TB/s.
Karena Qualcomm tidak mengungkapkan angka performa aktual, sulit untuk membandingkan HBC dengan penawaran GUC. Namun, kelemahan terbesar dari HBC adalah Qualcomm tidak memberi tahu apa yang sebenarnya dilakukan oleh akselerator HBC. Secara teori, bisa berupa mesin near-memory khusus transformer, kumpulan tensor core yang lebih umum, atau semacam logika prapemrosesan untuk inferensi atau pelatihan AI.

Bersamaan dengan teknologi HBC, Qualcomm juga mengungkapkan peta jalan HBC mereka. Akselerator AI200 perusahaan, yang akan hadir akhir tahun ini, akan mengandalkan LPDDR5X dan menawarkan 43 TB RAM per rak. Penerusnya, AI250, akan mengandalkan HBC Generasi ke-1 yang menawarkan bandwidth 18X lipat dari AI200. AI300 akan menggunakan HBC Generasi ke-2 yang memberikan bandwidth 54X lipat dari AI300.
Langkah Qualcomm ini menunjukkan keseriusan mereka dalam pasar AI yang semakin kompetitif. Dengan pendekatan yang lebih efisien secara daya dan biaya, arsitektur HBC berpotensi menjadi solusi alternatif yang menarik bagi pusat data yang ingin meningkatkan performa AI tanpa harus bergantung pada memori HBM yang mahal.
Qualcomm juga terus memperkuat posisinya di pasar AI melalui berbagai inisiatif strategis. Perusahaan baru-baru ini melakukan akuisisi senilai US$4 miliar untuk memperkuat target pasar AI mereka. Selain itu, perusahaan juga merilis Snapdragon C untuk laptop entry-level dengan harga sekitar Rp4 jutaan, menunjukkan ekspansi mereka ke berbagai segmen pasar.
Inovasi HBC ini juga muncul di tengah persaingan ketat di industri semikonduktor. Kehadiran Exynos 2600 dari Samsung disebut-sebut membuat Qualcomm dan Apple mulai melirik perkembangan teknologi proses terbaru. Namun, dengan arsitektur HBC, Qualcomm menunjukkan bahwa mereka tidak hanya fokus pada prosesor, tetapi juga pada solusi memori yang lebih efisien.
Meskipun masih banyak detail teknis yang belum diungkapkan, pengumuman Qualcomm HBC ini menandai langkah penting dalam upaya mengatasi memory wall yang selama ini membatasi performa AI. Dengan pendekatan near-memory compute yang inovatif, Qualcomm berpotensi memberikan solusi yang lebih terjangkau dan efisien bagi industri AI.

Perbandingan dengan teknologi HBM menunjukkan bahwa pendekatan Qualcomm memiliki beberapa keunggulan signifikan. HBM memang menawarkan bandwidth tinggi, namun biaya produksinya mahal karena memerlukan kemasan canggih dan interposer silikon. Sebaliknya, HBC menggunakan kemasan standar dan memori LPDDR yang lebih murah, sehingga dapat memberikan solusi dengan biaya lebih rendah tanpa mengorbankan performa.
Namun, masih ada pertanyaan tentang seberapa efektif HBC dalam berbagai skenario beban kerja AI. Tanpa pengungkapan spesifikasi detail dan benchmark performa, sulit untuk menilai secara objektif klaim Qualcomm. Industri masih menunggu data lebih lanjut untuk memvalidasi apakah arsitektur ini benar-benar dapat menjadi terobosan seperti yang diklaim.
Yang jelas, Qualcomm telah menunjukkan komitmennya untuk berinovasi di pasar AI. Dengan peta jalan yang jelas dari AI200 hingga AI300, perusahaan tampaknya serius ingin menjadi pemain utama di segmen ini. Apakah HBC akan menjadi standar baru dalam arsitektur memori AI atau hanya akan menjadi catatan kaki dalam sejarah, waktu yang akan menjawab.
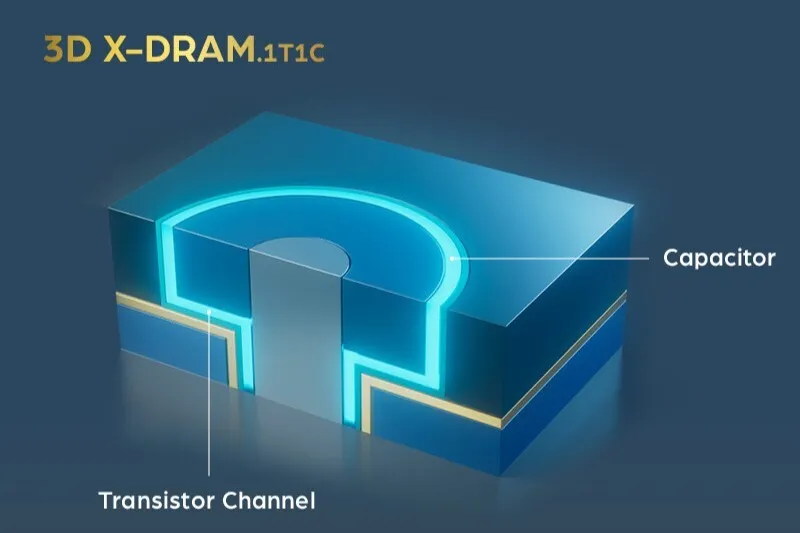
Sementara itu, industri semikonduktor terus bergerak maju dengan berbagai inovasi. NEO Semiconductor baru saja mengumumkan bahwa 3D X-DRAM revolusioner mereka untuk prosesor AI telah melewati validasi proof-of-concept. Samsung juga menunjukkan mockup HBM5 pertama mereka dengan teknologi pendinginan Heat Path Block. Semua perkembangan ini menunjukkan bahwa perlombaan untuk menciptakan solusi memori AI terbaik semakin memanas.
Bagi Qualcomm, keberhasilan HBC akan sangat bergantung pada adopsi pasar. Perusahaan perlu meyakinkan produsen server dan pusat data bahwa arsitektur ini menawarkan nilai tambah yang signifikan dibandingkan solusi yang sudah ada. Dengan klaim bandwidth-per-watt yang lebih tinggi dan biaya yang lebih rendah, HBC memiliki argumen yang kuat, namun implementasi nyata akan menjadi ujian sebenarnya.

Ke depannya, Qualcomm berencana untuk terus mengembangkan teknologi HBC melalui beberapa generasi. AI250 dengan HBC Generasi ke-1 dijanjikan akan memberikan peningkatan bandwidth 18X lipat, sementara AI300 dengan HBC Generasi ke-2 akan memberikan peningkatan 54X lipat. Angka-angka ini, jika terealisasi, akan menjadi lompatan performa yang sangat signifikan dalam industri AI.
Dengan segala kelebihan dan tantangannya, Qualcomm HBC tetap menjadi salah satu inovasi paling menarik di dunia arsitektur memori AI tahun ini. Keberhasilannya tidak hanya akan menguntungkan Qualcomm, tetapi juga dapat membuka jalan bagi pendekatan baru dalam merancang sistem AI yang lebih efisien dan terjangkau.




Komentar
Belum ada komentar.